How do we know for sure that a Gibbs Sampler of Section 1 ever stabilizes, and what determines the limiting value of p? We show that the D's of Section 1 form a 2-state Markov Chain and apply the results we established in Session 2.
2.1. A Markov Chain
We will now derive the key equation showing that the D-process is a Markov Chain. It uses the conditional distributions T|D and D|T to express the transition probabilities of the chain:
| P{D(m+1)=j|D(m)=i} | = Sk P{T(m)=k, D(m+1)=j|D(m)=i} |
| = Sk P{T(m)=k|D(m)=i} P{D(m+1)=j|T(m)=k, D(m)=i} | |
| = Sk P{D(m+1)=j|T(m)=k} P{T(m)=k|D(m)=i}, |
for m = 1, 2, 3, ... and i, j, k = 0, 1.
The first equality takes into account that either T(m) = 0 or T(m) = 1 just before the value of D(m+1) is simulated. The second uses the definition of conditional probability. The third uses the fact that the earlier condition D(m) = i is irrelevant once we are given the later information that T(m) = k, so that
P{D(m+1)=j|D(m)=i, T(m)=k} = P{D(m+1)=j|T(m)=k}.
This equation that is similar to the Markov Property discussed in Session 2, but it involves both D(m) and T(m) and so refers to "half-steps" of the simulation process. There are two simulated random events in each "full" step and each one of uses only the most recent previous result.
With the same values of h, q, g and d as in Section 1, the key equation for the transitional structure of the D-process is equivalent to the matrix equation
| P | = QR |
P is the transition matrix of the Markov Chain D(1), D(2), ..., which has state space {0, 1}. For example, the upper-left element is
| p00 | = P{D(m+1)=0|D(m)=0} |
| = P{D(m+1)=0|T(m)=0} P{T(m)=0|D(m)=0} + P{D(m+1)=0|T(m)=1} P{T(m)=1|D(m)=0} | |
| = P{T(m)=0|D(m)=0} P{D(m+1)=0|T(m)=0} + P{T(m)=1|D(m)=0} P{D(m+1)=0|T(m)=1} | |
| = qd + q*g* = (0.97)(0.9998) + (0.03)(0.5976) = 0.9877. |
2.2. Limiting distribution of this chain
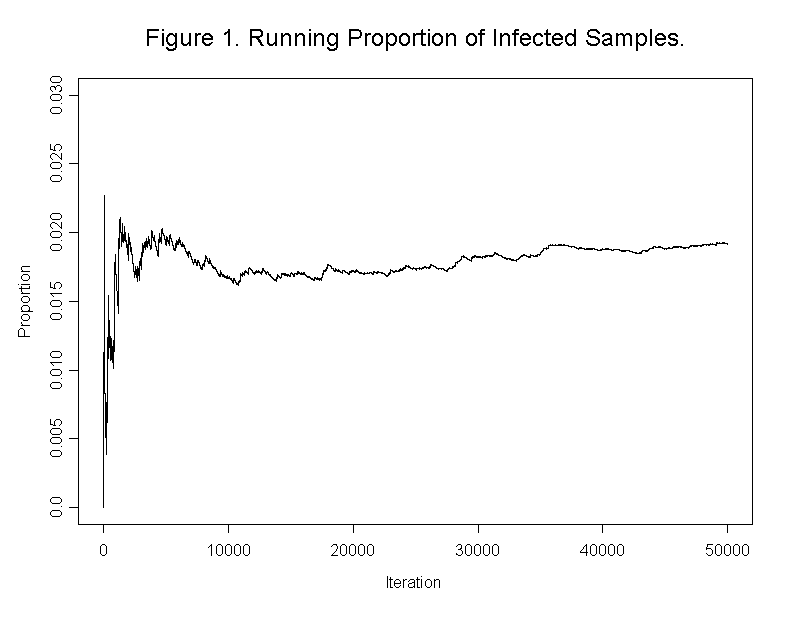
Because P has all positive elements, we know from Session 2 that the D-process settles down to a limiting distribution. From the agreement of the results in Table 1 and from the stability achieved for a typical run as shown in Figure 1, we conclude that 50,000 iterations were more than sufficient for the chain to reach its steady state.
As mentioned above (and proved in Session 2), it was not really necessary to use simulation to find the limiting distribution l of this chain. This distribution is the solution of the matrix equation lP = l which, upon solving two equations in two unknowns, is seen to be l = (p*, p) = (0.98, 0.02). The simulated values in Section 1 came quite close to the true value of p.
Problems:
2.1. Compute the matrix P = QR in the following circumstances:
(a) Express the matrix P in terms of the parameters h, q, g and d (using *s as needed). Substitute the numerical values of the parameters for the ELISA test discussed in this session to obtain the numerical result for P shown in Section 2.1. [One of the four entries of the matrix is stated in the required form at the very end of Section 2.1; find the other three.]
(b) A screening test for a certain parasitic infection in humans has sensitivity 80% and specificity 70%. Suppose that in a particular population the predictive values of positive and negative tests are 72.73% and 77.78% respectively. Find the P-matrix that corresponds to the the Gibbs Sampler in this situation.
2.2. In each of the following circumstances use algebraic methods to find prevalence.
(a) Use the P-matrix given at the end of Section 2.1 and the parameter values used throughout the text of this session to verify that the prevalence of the virus in units of blood at the site of interest is 2%. That is, verify the claim at the end of Section 2.2. (Recall that the two components of the steady-state vector l must sum to 1.) Compare this "linear-algebra" solution with the solution in Problem 1.1.
(b) For the screening test of problem 2.1(b), solve the matrix equation lP = l to find the prevalence of parasitic infections in the population described.
2.3. (Computer Simulation) Use the Gibbs Sampler to obtain the prevalence for the situation described in Problems 2.1(b) and 2.2(b). Do 10 runs with each starting value (20 in all). Use simulation runs of 100,000 steps with a burn-in period of 50,000. Why might you expect faster convergence here than for the ELISA test considered in this session?