The two-step transition probabilities are found by taking into account whether the value
of the chain at the intermediate step is 0 or 1. For example,
p01(2) = P{X(3)=1|X(1)=0} =
p00 p01 +
p01 p11 =
a(2 – a – b).
The probabilities of two-step transitions from 0 to 0, 1 to 0, and 1 to 1 are found similarly. Thus, the two-step transition matrix is P2 (obtained by ordinary matrix multiplication).
By induction (see the section below), the n-step transition matrix Pn can be expressed as the sum of two matrices:
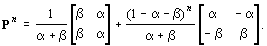
The first term in this sum does not depend on n. The second depends on n only via the exponent in the constant (scalar) multiplier; this term vanishes as n approaches infinity provided that |D| = |1 – a – b| < 1, which is guaranteed by our original restriction that all elements of P be positive. This result not only shows that Pn converges to a limit but also that the convergence takes place at a relatively rapid "geometric" rate.
Technical notes: Here we focus on cases were P has all positive elements.
However, the P-matrix for a so-called ergodic two-state chain either
has all positive elements or has one of a and
b (but not both) equal to 1. This is equivalent to saying that
P2 has all positive elements. The condition |D| < 1
required for convergence above includes not only ergodic chains, but also the "absorbing"
cases (either a or b, not both,
equal to 0), which have degenerate limiting distributions.
The upper-right element of the matrix Pn is the n-step
transition probability
p01(n) = P{X(n+m)=1|X(m)=0}.
We have just seen that, as n approaches infinity, p01(n)
approaches a/(a + b).
Similarly, looking at the lower-right element of Pn,
we find that p11(n) also approaches
a/(a + b).
In the long run, such a Markov chain "forgets" where it started.
Regardless of the starting value of the process, in the long run we have simply
p = P(X(¥) = 1)
= a/(a + b).
Similarly, looking at the elements in the first column of Pn,
we have the long-run probability
p* = P{X(¥) = 0}
= b/(a + b).
We say that the limiting distribution of X is given by the vector
l
= (p*, p) = (b/ (a + b), a/(a + b)).